Use Vantage from a Jupyter notebook
Author: Adam Tworkiewicz
Last updated: November 10th, 2022
| This how-to shows you how to add Teradata Extensions to a Jupyter Notebooks environment. A hosted version of Jupyter Notebooks integrated with Teradata Extensions and analytics tools is available for functional testing for free at https://clearscape.teradata.com. |
Overview
In this how-to we will go through the steps for connecting to Teradata Vantage from a Jupyter notebook.
| If you need a test instance of Vantage, you can provision one for free at https://clearscape.teradata.com. |
Options
There are a couple of ways to connect to Vantage from a Jupyter Notebook:
-
Use python or R libraries in a regular Python/R kernel notebook - this option works well when you are in a restricted environment that doesn’t allow you to spawn your own Docker images. Also, it’s useful in traditional datascience scenarios when you have to mix SQL and Python/R in a notebook. If you are proficient with Jupyter and have your own set of preferred libraries and extensions, start with this option.
-
Use the Teradata Jupyter Docker image - the Teradata Jupyter Docker image bundles the Teradata SQL kernel (more on this later),
teradatamlandtdplyrlibraries, python and R drivers. It also contains Jupyter extensions that allow you to manage Teradata connections, explore objects in Vantage database. It’s convenient when you work a lot with SQL or would find a visual Navigator helpful. If you are new to Jupyter or if you prefer to get a currated assembly of libraries and extensions, start with this option.
Teradata libraries
This option uses a regular Jupyter Lab notebook. We will see how to load the Teradata Python driver and use it from Python code. We will also examine ipython-sql extension that adds support for SQL-only cells.
-
We start with a plain Jupyter Lab notebook. Here, I’m using docker but any method of starting a notebook, including Jupyter Hub, Google Cloud AI Platform Notebooks, AWS SageMaker Notebooks, Azure ML Notebooks will do.
docker run --rm -p 8888:8888 -e JUPYTER_ENABLE_LAB=yes \ -v "${PWD}":/home/jovyan/work jupyter/datascience-notebook -
Docker logs will display the url that you need to go to:
Entered start.sh with args: jupyter lab Executing the command: jupyter lab .... To access the server, open this file in a browser: file:///home/jovyan/.local/share/jupyter/runtime/jpserver-7-open.html Or copy and paste one of these URLs: http://d5c2323ae5db:8888/lab?token=5fb43e674367c6895e8c2404188aa550b5c7bdf96f5b4a3a or http://127.0.0.1:8888/lab?token=5fb43e674367c6895e8c2404188aa550b5c7bdf96f5b4a3a -
We will open a new notebook and create a cell to install the required libraries:
I’ve published a notebook with all the cells described below on GitHub: https://github.com/Teradata/quickstarts/blob/main/modules/ROOT/attachments/vantage-with-python-libraries.ipynb import sys !{sys.executable} -m pip install teradatasqlalchemy -
Now, we will import
Pandasand define the connection string to connect to Teradata. Since I’m running my notebook in Docker on my local machine and I want to connect to a local Vantage Express VM, I’m usinghost.docker.internalDNS name provided by Docker to reference the IP of my machine.import pandas as pd # Define the db connection string. Pandas uses SQLAlchemy connection strings. # For Teradata Vantage, it's teradatasql://username:password@host/database_name . # See https://pypi.org/project/teradatasqlalchemy/ for details. db_connection_string = "teradatasql://dbc:dbc@host.docker.internal/dbc" -
I can now call Pandas to query Vantage and move the result to a Pandas dataframe:
pd.read_sql("SELECT * FROM dbc.dbcinfo", con = db_connection_string) -
The syntax above is concise but it can get tedious if all you need is to explore data in Vantage. We will use
ipython-sqland its%%sqlmagic to create SQL-only cells. We start with importing the required libraries.import sys !{sys.executable} -m pip install ipython-sql teradatasqlalchemy -
We load
ipython-sqland define the db connection string:%load_ext sql # Define the db connection string. The sql magic uses SQLAlchemy connection strings. # For Teradata Vantage, it's teradatasql://username:password@host/database_name . # See https://pypi.org/project/teradatasqlalchemy/ for details. %sql teradatasql://dbc:dbc@host.docker.internal/dbc -
We can now use
%sqland%%sqlmagic. Let’s say we want to explore data in a table. We can create a cell that says:%%sql SELECT * FROM dbc.dbcinfo -
If we want to move the data to a Pandas frame, we can say:
result = %sql SELECT * FROM dbc.dbcinfo result.DataFrame()
There are many other features that ipython-sql provides, including variable substitution, plotting with matplotlib, writting results to a local csv file or back to the database. See the demo notebook for examples and ipython-sql github repo for a complete reference.
Teradata Jupyter Docker image
The Teradata Jupyter Docker image builds on jupyter/datascience-notebook Docker image. It adds the Teradata SQL kernel, Teradata Python and R libraries, Jupyter extensions to make you productive while interacting with Teradata Vantage. The image also contains sample notebooks that demonstrate how to use the SQL kernel and Teradata libraries.
The SQL kernel and Teradata Jupyter extensions are useful for people that spend a lot of time with the SQL interface. Think about it as a notebook experience that, in many cases, is more convenient than using Teradata Studio. The Teradata Jupyter Docker image doesn’t try to replace Teradata Studio. It doesn’t have all the features. It’s designed for people who need a lightweight, web-based interface and enjoy the notebook UI.
The Teradata Jupyter Docker image can be used when you want to run Jupyter locally or you have a place where you can run custom Jupyter docker images. The steps below demonstrate how to use the image locally.
-
Run the image:
By passing -e "accept_license=Yyou accept the license agreement for Teradata Jupyter Extensions.docker volume create notebooks docker run -e "accept_license=Y" -p :8888:8888 \ -v notebooks:/home/jovyan/JupyterLabRoot \ teradata/jupyterlab-extensions -
Docker logs will display the url that you need to go to. For example, this is what I’ve got:
Starting JupyterLab ... Docker Build ID = 3.2.0-ec02012022 Using unencrypted HTTP Enter this URL in your browser: http://localhost:8888?token=96a3ab874a03779c400966bf492fe270c2221cdcc74b61ed * Or enter this token when prompted by Jupyter: 96a3ab874a03779c400966bf492fe270c2221cdcc74b61ed * If you used a different port to run your Docker, replace 8888 with your port number
-
Open up the URL and use the file explorer to open the following notebook:
jupyterextensions → notebooks → sql → GettingStartedDemo.ipynb. -
Go through the demo of the Teradata SQL Kernel:
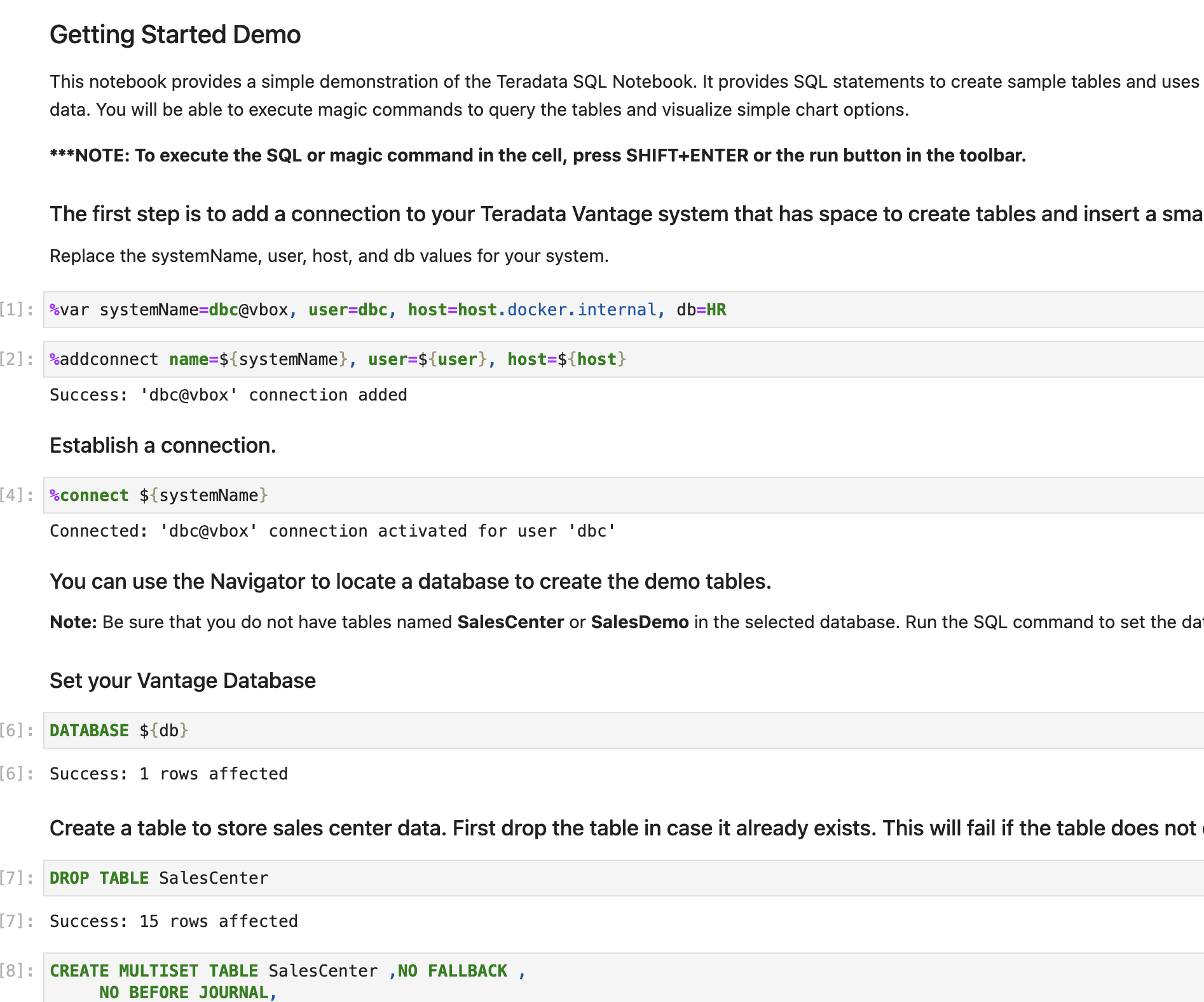
Summary
This quick start covered different options to connect to Teradata Vantage from a Jupyter Notebook. We learned about the Teradata Jupyter Docker image that bundles multiple Teradata Python and R libraries. It also provides an SQL kernel, database object explorer and connection management. These features are useful when you spend a lot of time with the SQL interface. For more traditional data science scenarios, we explored the standalone Teradata Python driver and integration through the ipython sql extension.
Further reading
| If you have any questions or need further assistance, please visit our community forum where you can get support and interact with other community members. |