Connect Teradata Vantage to Salesforce using Amazon Appflow
Author: Wenjie Tehan
Last updated: February 14th, 2022
Overview
This how-to describes the process to migrate data between Salesforce and Teradata Vantage. It contains two use cases:
-
Retrieve customer information from Salesforce, and combine it with order and shipping information from Vantage to derive analytical insights.
-
Update
newleadstable on Vantage with the Salesforce data, then add the new lead(s) back to Salesforce using AppFlow.
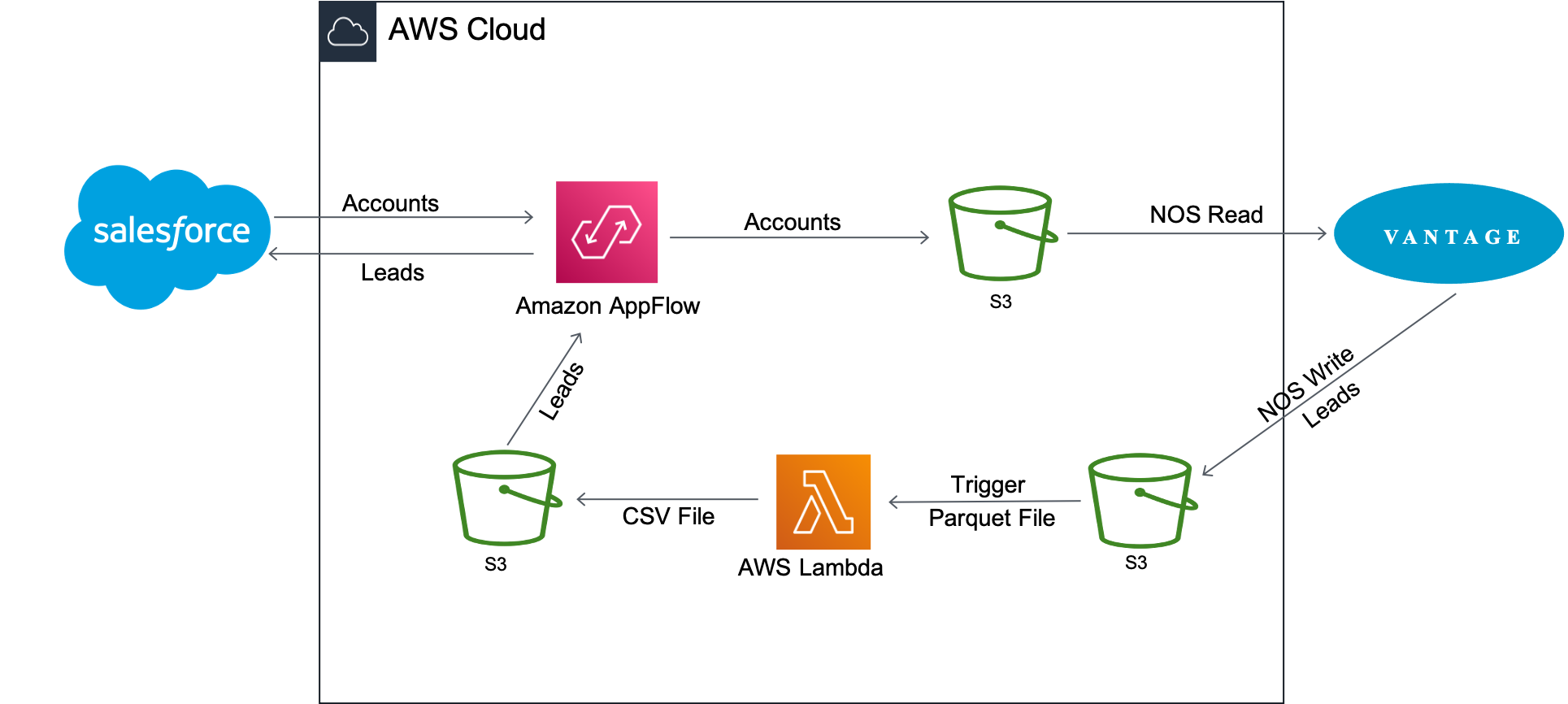
Amazon AppFlow transfers the customer account data from Salesforce to Amazon S3. Vantage then uses Native Object Store (NOS) read functionality to join the data in Amazon S3 with data in Vantage with a single query.
The account information is used to update the newleads table on Vantage. Once the table is updated, Vantage writes it back to the Amazon S3 bucket with NOS Write. A Lambda function is triggered upon arrival of the new lead data file to convert the data file from Parquet format to CSV format, and AppFlow then inserts the new lead(s) back into Salesforce.
About Amazon AppFlow
Amazon AppFlow is a fully managed integration service that enables users to securely transfer data between Software-as-a-Service (SaaS) applications like Salesforce, Marketo, Slack, and ServiceNow, and AWS services like Amazon S3 and Amazon Redshift. AppFlow automatically encrypts data in motion, and allows users to restrict data from flowing over the public internet for SaaS applications that are integrated with AWS PrivateLink, reducing exposure to security threats.
As of today, Amazon AppFlow has 16 sources to choose from, and can send the data to four destinations.
About Teradata Vantage
Teradata Vantage is the connected multi-cloud data platform for enterprise analytics, solving data challenges from start to scale.
Vantage enables companies to start small and elastically scale compute or storage, paying only for what they use, harnessing low-cost object stores and integrating their analytic workloads. Vantage supports R, Python, Teradata Studio, and any other SQL-based tools.
Vantage combines descriptive, predictive, prescriptive analytics, autonomous decision-making, ML functions, and visualization tools into a unified, integrated platform that uncovers real-time business intelligence at scale, no matter where the data resides.
Teradata Vantage Native Object Store (NOS) can be used to explore data in external object stores, like Amazon S3, using standard SQL. No special object storage-side compute infrastructure is required to use NOS. Users can explore data located in an Amazon S3 bucket by simply creating a NOS table definition that points to your bucket. With NOS, you can quickly import data from Amazon S3 or even join it with other tables in the Vantage database.
Prerequisites
You are expected to be familiar with Amazon AppFlow service and Teradata Vantage.
You will need the following accounts, and systems:
-
Access to a Teradata Vantage instance.
If you need a test instance of Vantage, you can provision one for free at https://clearscape.teradata.com. -
An AWS account with the role that can create and run flows.
-
An Amazon S3 bucket to store Salesforce data (i.e., ptctsoutput)
-
An Amazon S3 bucket to store raw Vantage data (Parquet file) (i.e., vantageparquet). This bucket needs to have policy to allow Amazon AppFlow access
-
An Amazon S3 bucket to store converted Vantage data (CSV file) (i.e., vantagecsv)
-
A Salesforce account that satisfies the following requirements:
-
Your Salesforce account must be enabled for API access. API access is enabled by default for Enterprise, Unlimited, Developer, and Performance editions.
-
Your Salesforce account must allow you to install connected apps. If this is disabled, contact your Salesforce administrator. After you create a Salesforce connection in Amazon AppFlow, verify that the connected app named "Amazon AppFlow Embedded Login App" is installed in your Salesforce account.
-
The refresh token policy for the "Amazon AppFlow Embedded Login App" must be set to "Refresh token is valid until revoked". Otherwise, your flows will fail when your refresh token expires.
-
You must enable Change Data Capture in Salesforce to use event-driven flow triggers. From Setup, enter "Change Data Capture" in Quick Find.
-
If your Salesforce app enforces IP address restrictions, you must whitelist the addresses used by Amazon AppFlow. For more information, see https://docs.aws.amazon.com/general/latest/gr/aws-ip-ranges.html[AWS IP address ranges] in the Amazon Web Services General Reference.
-
If you are transferring over 1 million Salesforce records, you cannot choose any Salesforce compound field. Amazon AppFlow uses Salesforce Bulk APIs for the transfer, which does not allow transfer of compound fields.
-
To create private connections using AWS PrivateLink, you must enable both "Manager Metadata" and "Manage External Connections" user permissions in your Salesforce account. Private connections are currently available in the us-east-1 and us-west-2 AWS Regions.
-
Some Salesforce objects can’t be updated, such as history objects. For these objects, Amazon AppFlow does not support incremental export (the "Transfer new data only" option) for schedule-triggered flows. Instead, you can choose the "Transfer all data" option and then select the appropriate filter to limit the records you transfer.
-
Procedure
Once you have met the prerequisites, follow these steps:
-
Create a Salesforce to Amazon S3 Flow
-
Exploring Data using NOS
-
Export Vantage Data to Amazon S3 using NOS
-
Create an Amazon S3 to Salesforce Flow
Create a Salesforce to Amazon S3 Flow
This step creates a flow using Amazon AppFlow. For this example, we’re using a Salesforce developer account to connect to Salesforce.
Go to AppFlow console, sign in with your AWS login credentials and click Create flow. Make sure you are in the right region, and the bucket is created to store Salesforce data.
Step 1: Specify flow details
This step provides basic information for your flow.
Fill in Flow name (i.e. salesforce) and Flow description (optional), leave Customize encryption settings (advanced) unchecked. Click Next.
Step 2: Configure flow
This step provides information about the source and destination for your flow. For this example, we will be using Salesforce as the source, and Amazon S3 as the destination.
-
For Source name, choose Salesforce, then Create new connection for Choose Salesforce connection.
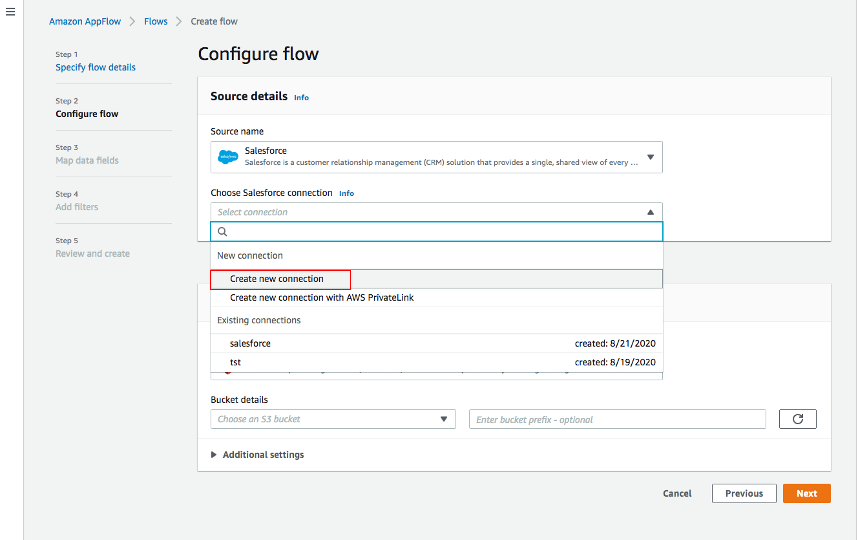
-
Use default for Salesforce environment and Data encryption. Give your connection a name (i.e. salesforce) and click Continue.
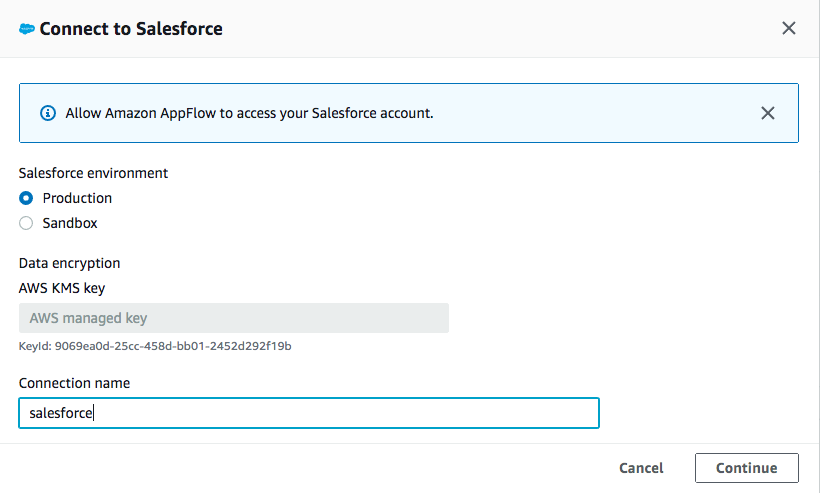
-
At the salesforce login window, enter your Username and Password. Click Log In
-
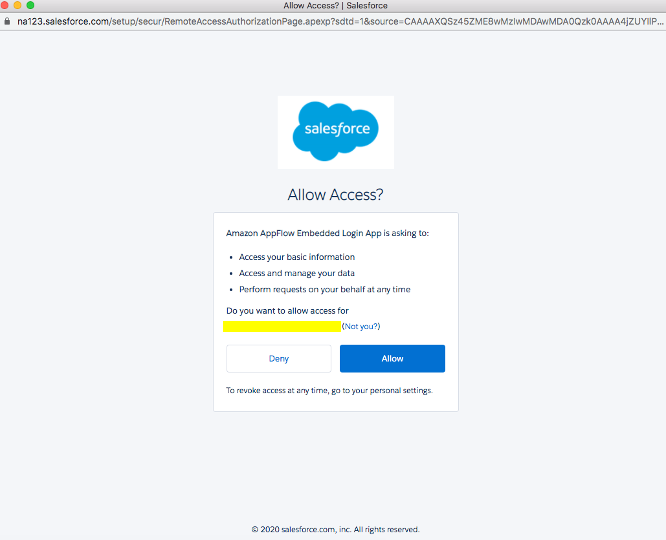
Click Allow to allow AppFlow to access your salesforce data and information.
-
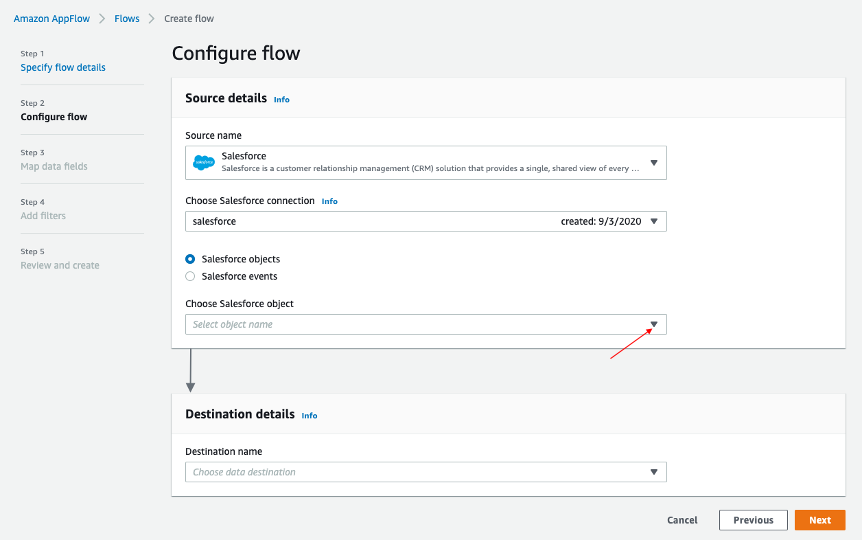
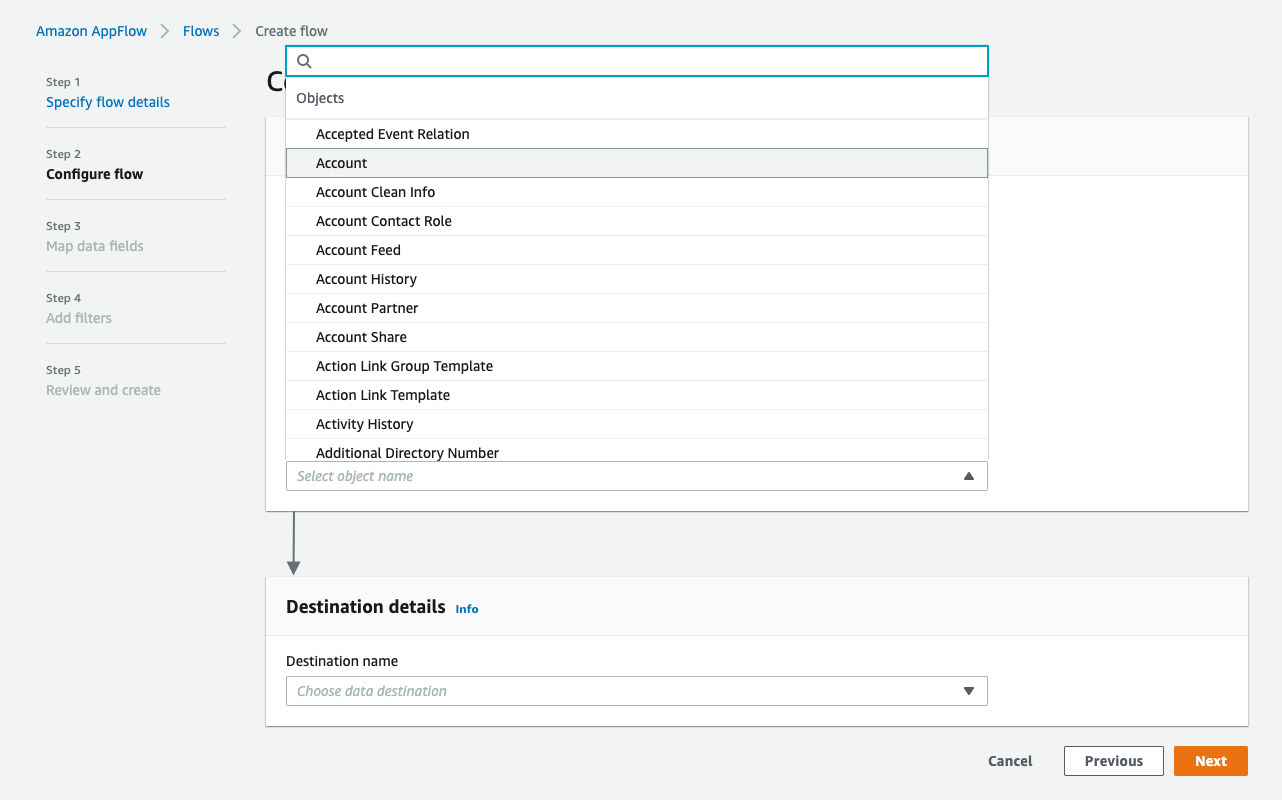
Back at the AppFlow Configure flow window, use Salesforce objects, and choose Account to be the Salesforce object.
-
Use Amazon S3 as Destination name. Pick the bucket you created earlier where you want the data to be stored (i.e., ptctsoutput).
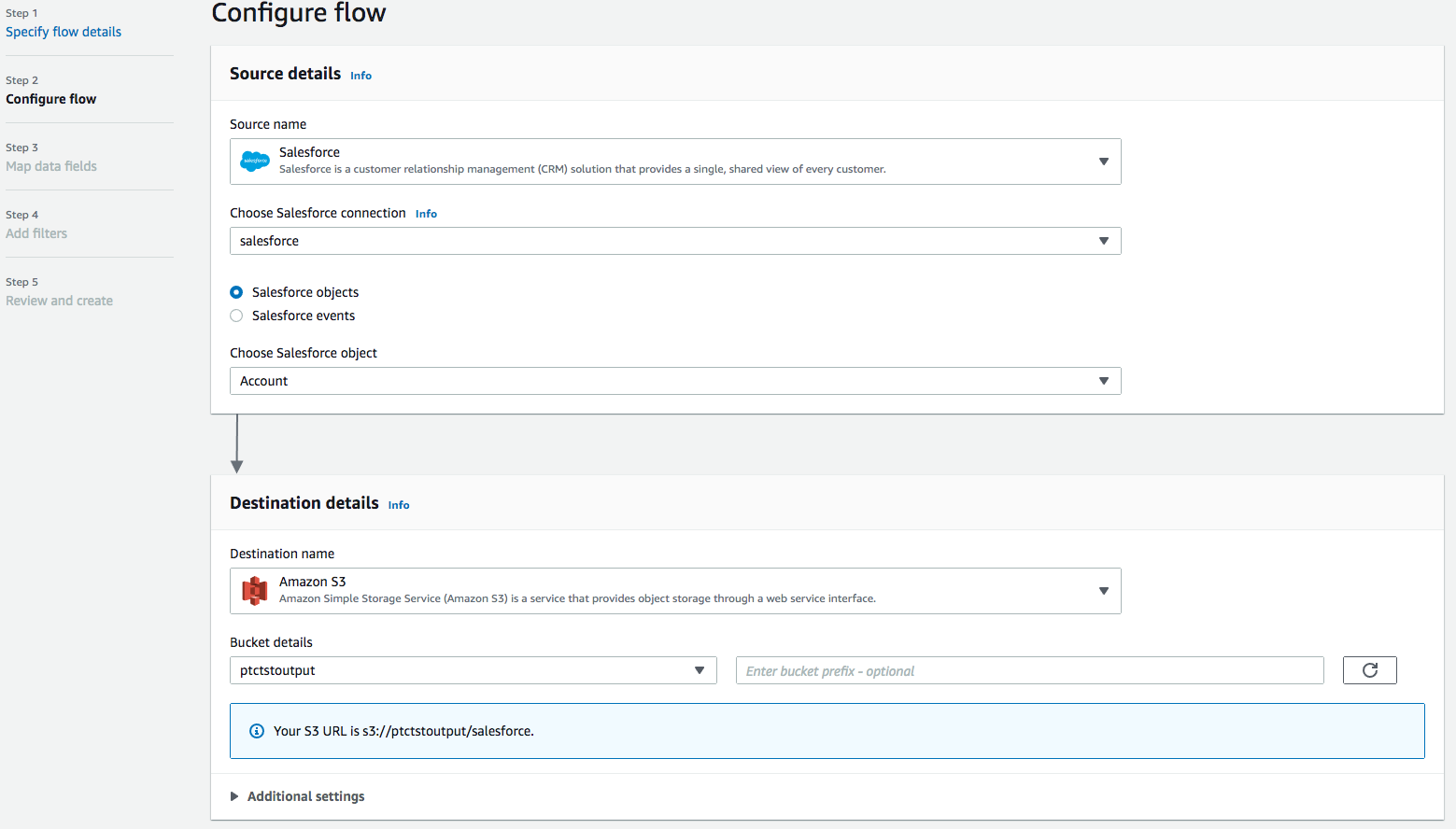
-
Flow trigger is Run on demand. Click Next.
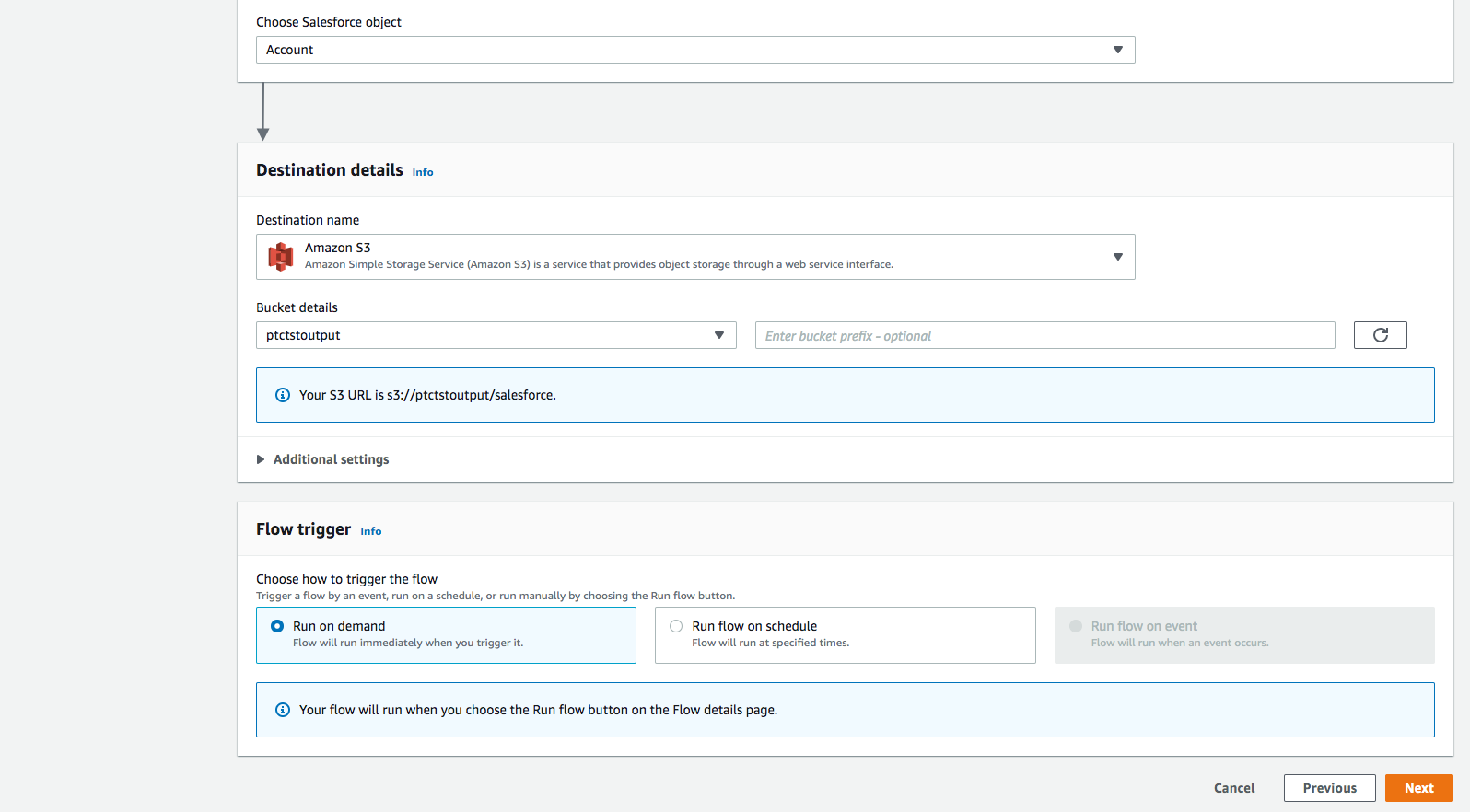
Step 3: Map data fields
This step determines how data is transferred from the source to the destination.
-
Use Manually map fields as Mapping method
-
For simplicity, choose Map all fields directly for Source to destination filed mapping.
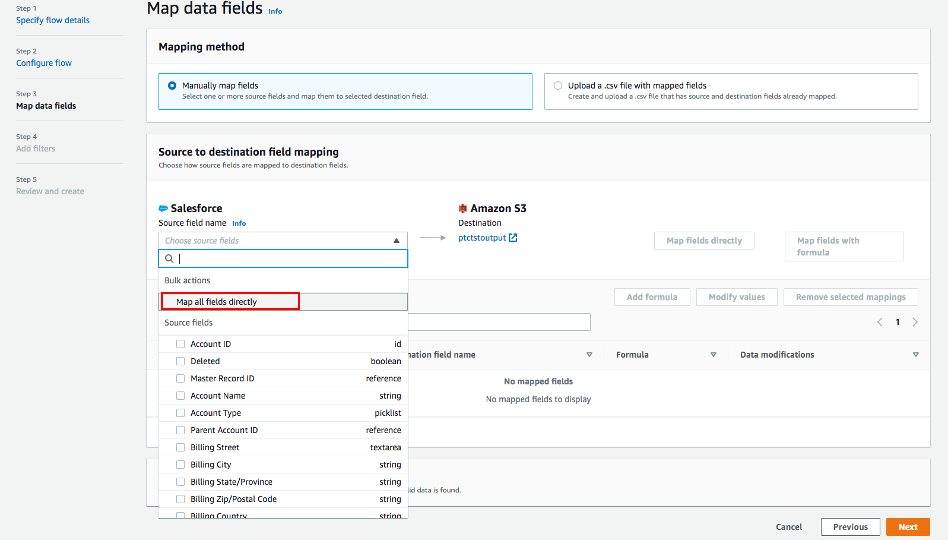
Once you click on "Map all fields directly", all the fields will show under Mapped fields. Click on the checkbox for the field(s) you want to Add formula (concatenates), Modify values (mask or truncate field values), or Remove selected mappings.
For this example, no checkbox will be ticked.
-
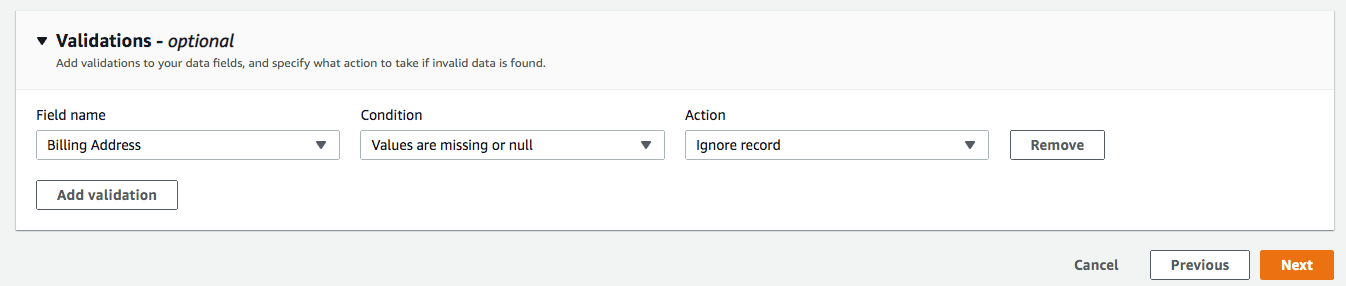
For Validations, add in a condition to ignore the record that contains no "Billing Address" (optional). Click Next.
Step 4: Add filters
You can specify a filter to determine which records to transfer. For this example, add a condition to filter out the records that are deleted (optional). Click Next.
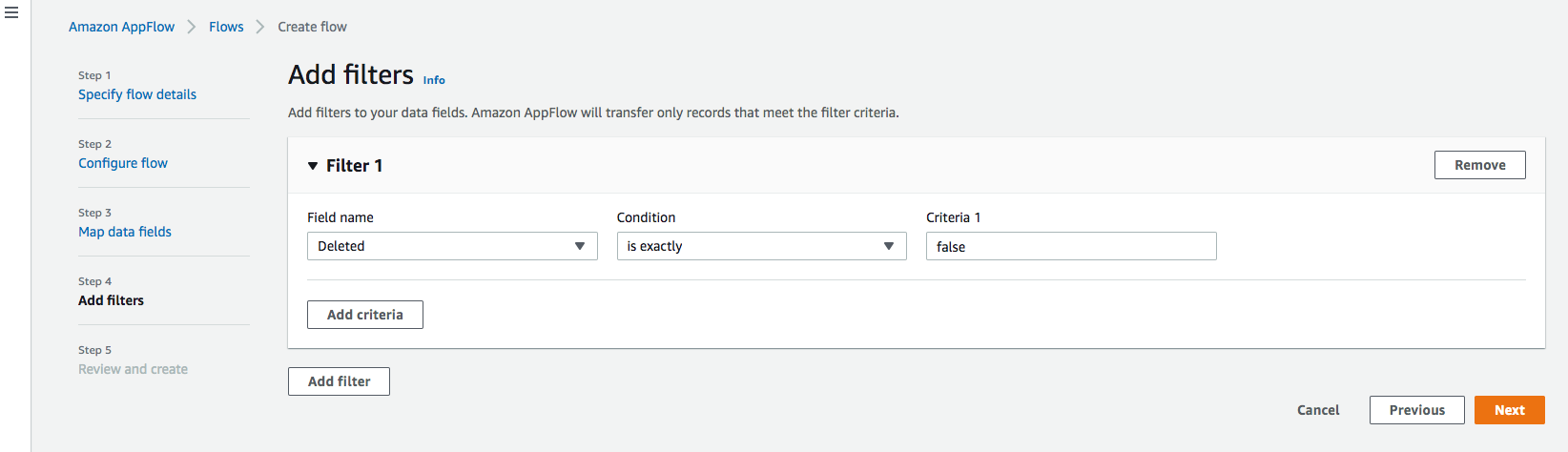
Step 5. Review and create
Review all the information you just entered. Modify if necessary. Click Create flow.
A message of successful flow creation will be displayed with the flow information once the flow is created,
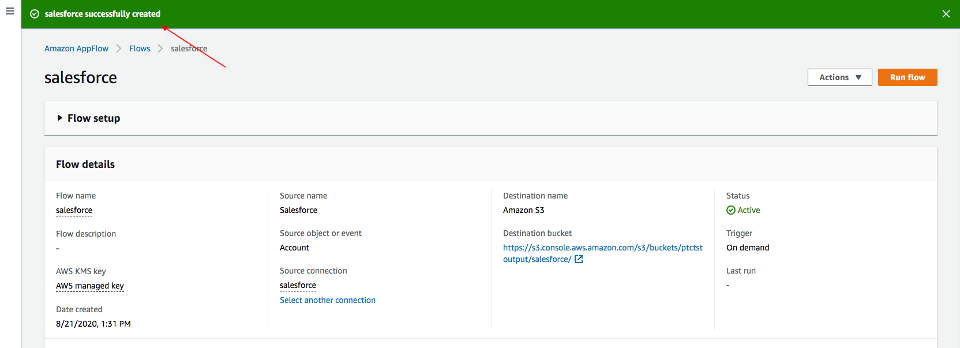
Run flow
Click Run flow on the upper right corner.
Upon completion of the flow run, message will be displayed to indicate a successful run.
Message example:

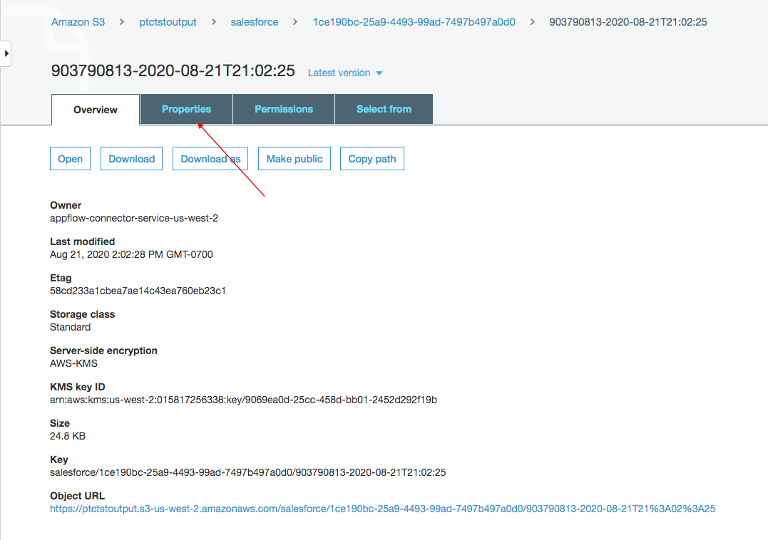
Click the link to the bucket to view data. Salesforce data will be in JSON format.
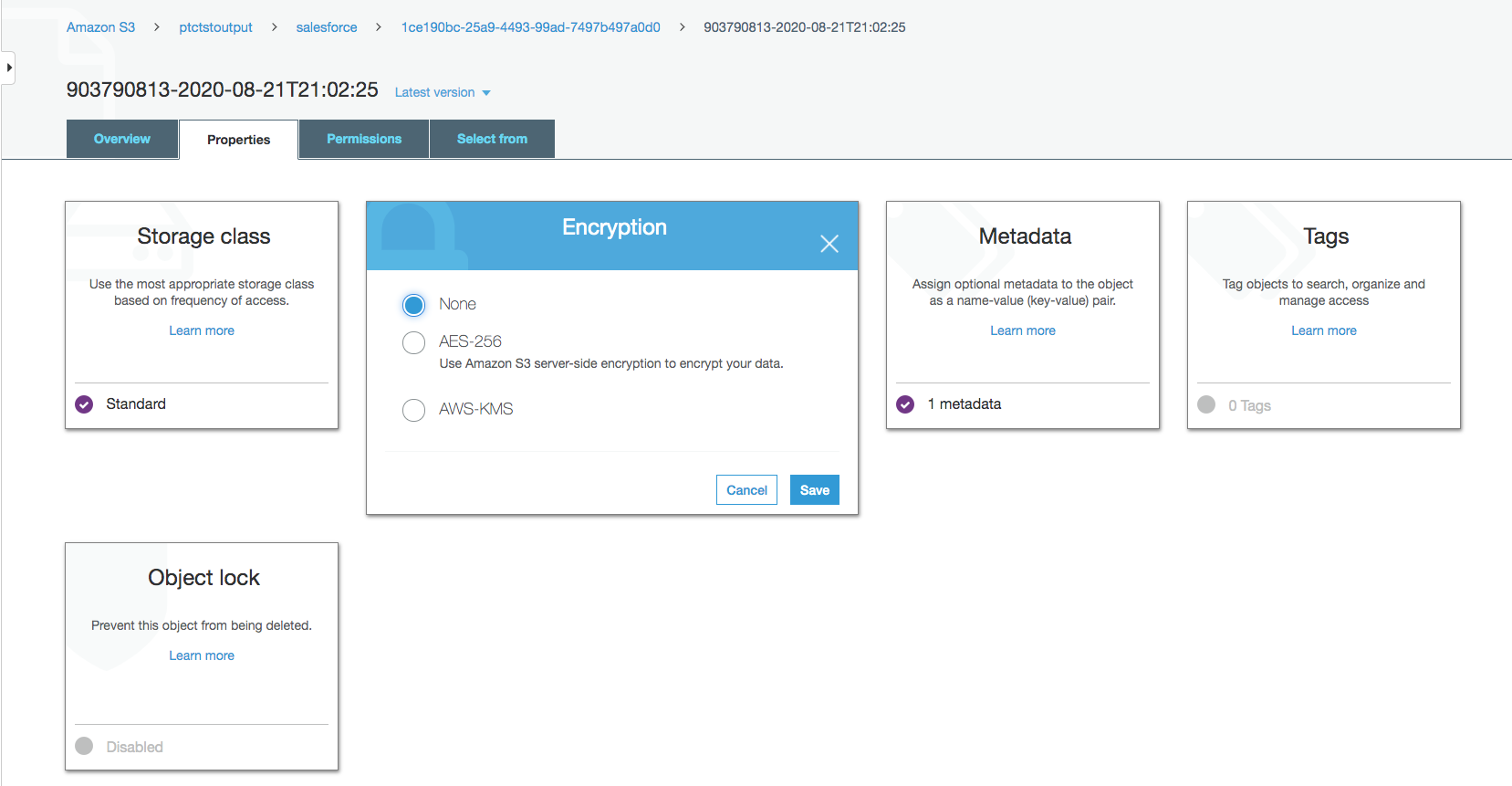
Change data file properties
By default, Salesforce data is encrypted. We need to remove the encryption for NOS to access it.
Click on the data file in your Amazon S3 bucket, then click the Properties tab.
Click on the AWS-KMS from Encryption and change it from AWS-KMS encryption to None. Click Save.
Exploring Data Using NOS
Native Object Store has built in functionalities to explore and analyze data in Amazon S3. This section lists a few commonly used functions of NOS.
Create Foreign Table
Foreign table allows the external data to be easily referenced within the Vantage Advanced SQL Engine and makes the data available in a structured relational format.
To create a foreign table, first login to Teradata Vantage system with your credentials. Create AUTHORIZATION object with access keys for Amazon S3 bucket access. Authorization object enhances security by establishing control over who is allowed to use a foreign table to access Amazon S3 data.
CREATE AUTHORIZATION DefAuth_S3
AS DEFINER TRUSTED
USER 'A*****************' /* AccessKeyId */
PASSWORD '********'; /* SecretAccessKey */"USER" is the AccessKeyId for your AWS account, and "PASSWORD" is the SecretAccessKey.
Create a foreign table against the JSON file on Amazon S3 using following command.
CREATE MULTISET FOREIGN TABLE salesforce,
EXTERNAL SECURITY DEFINER TRUSTED DefAuth_S3
(
Location VARCHAR(2048) CHARACTER SET UNICODE CASESPECIFIC,
Payload JSON(8388096) INLINE LENGTH 32000 CHARACTER SET UNICODE
)
USING
(
LOCATION ('/S3/s3.amazonaws.com/ptctstoutput/salesforce/1ce190bc-25a9-4493-99ad-7497b497a0d0/903790813-2020-08-21T21:02:25')
);At a minimum, the foreign table definition must include a table name and location clause (highlighted in yellow) which points to the object store data. The Location requires a top-level single name, referred to as a "bucket" in Amazon.
If the file name doesn’t have standard extension (.json, .csv, .parquet) at the end, the Location and Payload columns definition is also required (highlighted in turquoise) to indicate the type of the data file.
Foreign tables are always defined as No Primary Index (NoPI) tables.
Once foreign table’s created, you can query the content of the Amazon S3 data set by doing "Select" on the foreign table.
SELECT * FROM salesforce;
SELECT payload.* FROM salesforce;The foreign table only contains two columns: Location and Payload. Location is the address in the object store system. The data itself is represented in the payload column, with the payload value within each record in the foreign table representing a single JSON object and all its name-value pairs.
Sample output from "SELECT * FROM salesforce;".
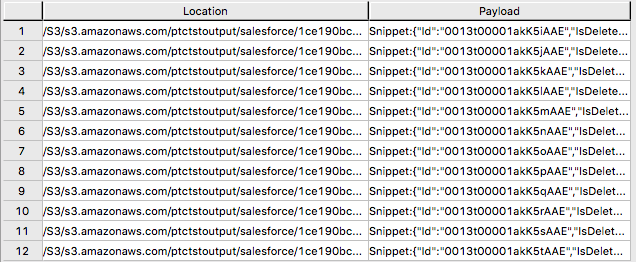
Sample output form "SELECT payload.* FROM salesforce;".

JSON_KEYS Table Operator
JSON data may contain different attributes in different records. To determine the full list of possible attributes in a data store, use JSON_KEYS:
|SELECT DISTINCT * FROM JSON_KEYS (ON (SELECT payload FROM salesforce)) AS j;Partial Output:

Create View
Views can simplify the names associated with the payload attributes, make it easier to code executable SQL against object store data, and hide the Location references in the foreign table to make it look like normal columns.
Following is a sample create view statement with the attributes discovered from the JSON_KEYS table operator above.
REPLACE VIEW salesforceView AS (
SELECT
CAST(payload.Id AS VARCHAR(20)) Customer_ID,
CAST(payload."Name" AS VARCHAR(100)) Customer_Name,
CAST(payload.AccountNumber AS VARCHAR(10)) Acct_Number,
CAST(payload.BillingStreet AS VARCHAR(20)) Billing_Street,
CAST(payload.BillingCity AS VARCHAR(20)) Billing_City,
CAST(payload.BillingState AS VARCHAR(10)) Billing_State,
CAST(payload.BillingPostalCode AS VARCHAR(5)) Billing_Post_Code,
CAST(payload.BillingCountry AS VARCHAR(20)) Billing_Country,
CAST(payload.Phone AS VARCHAR(15)) Phone,
CAST(payload.Fax AS VARCHAR(15)) Fax,
CAST(payload.ShippingStreet AS VARCHAR(20)) Shipping_Street,
CAST(payload.ShippingCity AS VARCHAR(20)) Shipping_City,
CAST(payload.ShippingState AS VARCHAR(10)) Shipping_State,
CAST(payload.ShippingPostalCode AS VARCHAR(5)) Shipping_Post_Code,
CAST(payload.ShippingCountry AS VARCHAR(20)) Shipping_Country,
CAST(payload.Industry AS VARCHAR(50)) Industry,
CAST(payload.Description AS VARCHAR(200)) Description,
CAST(payload.NumberOfEmployees AS VARCHAR(10)) Num_Of_Employee,
CAST(payload.CustomerPriority__c AS VARCHAR(10)) Priority,
CAST(payload.Rating AS VARCHAR(10)) Rating,
CAST(payload.SLA__c AS VARCHAR(10)) SLA,
CAST(payload.AnnualRevenue AS VARCHAR(10)) Annual_Revenue,
CAST(payload."Type" AS VARCHAR(20)) Customer_Type,
CAST(payload.Website AS VARCHAR(100)) Customer_Website,
CAST(payload.LastActivityDate AS VARCHAR(50)) Last_Activity_Date
FROM salesforce
);SELECT * FROM salesforceView;Partial output:

READ_NOS Table Operator
READ_NOS table operator can be used to sample and explore a percent of the data without having first defined a foreign table, or to view a list of the keys associated with all the objects specified by a Location clause.
SELECT top 5 payload.*
FROM READ_NOS (
ON (SELECT CAST(NULL AS JSON CHARACTER SET Unicode))
USING
LOCATION ('/S3/s3.amazonaws.com/ptctstoutput/salesforce/1ce190bc-25a9-4493-99ad-7497b497a0d0/903790813-2020-08-21T21:02:25')
ACCESS_ID ('A**********') /* AccessKeyId */
ACCESS_KEY ('***********') /* SecretAccessKey */
) AS D
GROUP BY 1;Output:

Join Amazon S3 Data to In-Database Tables
Foreign table can be joined with a table(s) in Vantage for further analysis. For example, ordering and shipping information are in Vantage in these three tables – Orders, Order_Items and Shipping_Address.
DDL for Orders:
CREATE TABLE Orders (
Order_ID INT NOT NULL,
Customer_ID VARCHAR(20) CHARACTER SET LATIN CASESPECIFIC,
Order_Status INT,
-- Order status: 1 = Pending; 2 = Processing; 3 = Rejected; 4 = Completed
Order_Date DATE NOT NULL,
Required_Date DATE NOT NULL,
Shipped_Date DATE,
Store_ID INT NOT NULL,
Staff_ID INT NOT NULL
) Primary Index (Order_ID);DDL for Order_Items:
CREATE TABLE Order_Items(
Order_ID INT NOT NULL,
Item_ID INT,
Product_ID INT NOT NULL,
Quantity INT NOT NULL,
List_Price DECIMAL (10, 2) NOT NULL,
Discount DECIMAL (4, 2) NOT NULL DEFAULT 0
) Primary Index (Order_ID, Item_ID);DDL for Shipping_Address:
CREATE TABLE Shipping_Address (
Customer_ID VARCHAR(20) CHARACTER SET LATIN CASESPECIFIC NOT NULL,
Street VARCHAR(100) CHARACTER SET LATIN CASESPECIFIC,
City VARCHAR(20) CHARACTER SET LATIN CASESPECIFIC,
State VARCHAR(15) CHARACTER SET LATIN CASESPECIFIC,
Postal_Code VARCHAR(10) CHARACTER SET LATIN CASESPECIFIC,
Country VARCHAR(20) CHARACTER SET LATIN CASESPECIFIC
) Primary Index (Customer_ID);And the tables have following data:
Orders:

Order_Items:

Shipping_Address:

By joining the salesforce foreign table to the established database table Orders, Order_Items and Shipping_Address, we can retrieve customer’s order information with customer’s shipping information.
SELECT
s.payload.Id as Customer_ID,
s.payload."Name" as Customer_Name,
s.payload.AccountNumber as Acct_Number,
o.Order_ID as Order_ID,
o.Order_Status as Order_Status,
o.Order_Date as Order_Date,
oi.Item_ID as Item_ID,
oi.Product_ID as Product_ID,
sa.Street as Shipping_Street,
sa.City as Shipping_City,
sa.State as Shipping_State,
sa.Postal_Code as Shipping_Postal_Code,
sa.Country as Shipping_Country
FROM
salesforce s, Orders o, Order_Items oi, Shipping_Address sa
WHERE
s.payload.Id = o.Customer_ID
AND o.Customer_ID = sa.Customer_ID
AND o.Order_ID = oi.Order_ID
ORDER BY 1;Results:
![]()
Import Amazon S3 Data to Vantage
Having a persistent copy of the Amazon S3 data can be useful when repetitive access of the same data is expected. NOS foreign table does not automatically make a persistent copy of the Amazon S3 data. A few approaches to capture the data in the database are described below:
A "CREATE TABLE AS … WITH DATA" statement can be used with the foreign table definition acting as the source table. Use this approach you can selectively choose which attributes within the foreign table payload that you want to include in the target table, and what the relational table columns will be named.
CREATE TABLE salesforceVantage AS (
SELECT
CAST(payload.Id AS VARCHAR(20)) Customer_ID,
CAST(payload."Name" AS VARCHAR(100)) Customer_Name,
CAST(payload.AccountNumber AS VARCHAR(10)) Acct_Number,
CAST(payload.BillingStreet AS VARCHAR(20)) Billing_Street,
CAST(payload.BillingCity AS VARCHAR(20)) Billing_City,
CAST(payload.BillingState AS VARCHAR(10)) Billing_State,
CAST(payload.BillingPostalCode AS VARCHAR(5)) Billing_Post_Code,
CAST(payload.BillingCountry AS VARCHAR(20)) Billing_Country,
CAST(payload.Phone AS VARCHAR(15)) Phone,
CAST(payload.Fax AS VARCHAR(15)) Fax,
CAST(payload.ShippingStreet AS VARCHAR(20)) Shipping_Street,
CAST(payload.ShippingCity AS VARCHAR(20)) Shipping_City,
CAST(payload.ShippingState AS VARCHAR(10)) Shipping_State,
CAST(payload.ShippingPostalCode AS VARCHAR(5)) Shipping_Post_Code,
CAST(payload.ShippingCountry AS VARCHAR(20)) Shipping_Country,
CAST(payload.Industry AS VARCHAR(50)) Industry,
CAST(payload.Description AS VARCHAR(200)) Description,
CAST(payload.NumberOfEmployees AS INT) Num_Of_Employee,
CAST(payload.CustomerPriority__c AS VARCHAR(10)) Priority,
CAST(payload.Rating AS VARCHAR(10)) Rating,
CAST(payload.SLA__c AS VARCHAR(10)) SLA,
CAST(payload."Type" AS VARCHAR(20)) Customer_Type,
CAST(payload.Website AS VARCHAR(100)) Customer_Website,
CAST(payload.AnnualRevenue AS VARCHAR(10)) Annual_Revenue,
CAST(payload.LastActivityDate AS DATE) Last_Activity_Date
FROM salesforce)
WITH DATA
NO PRIMARY INDEX;-
SELECT* * FROM salesforceVantage;partial results:

An alternative to using foreign table is to use the READ_NOS table operator. This table operator allows you to access data directly from an object store without first building a foreign table. Combining READ_NOS with a CREATE TABLE AS clause to build a persistent version of the data in the database.
CREATE TABLE salesforceReadNOS AS (
SELECT
CAST(payload.Id AS VARCHAR(20)) Customer_ID,
CAST(payload."Name" AS VARCHAR(100)) Customer_Name,
CAST(payload.AccountNumber AS VARCHAR(10)) Acct_Number,
CAST(payload.BillingStreet AS VARCHAR(20)) Billing_Street,
CAST(payload.BillingCity AS VARCHAR(20)) Billing_City,
CAST(payload.BillingState AS VARCHAR(10)) Billing_State,
CAST(payload.BillingPostalCode AS VARCHAR(5)) Billing_Post_Code,
CAST(payload.BillingCountry AS VARCHAR(20)) Billing_Country,
CAST(payload.Phone AS VARCHAR(15)) Phone,
CAST(payload.Fax AS VARCHAR(15)) Fax,
CAST(payload.ShippingStreet AS VARCHAR(20)) Shipping_Street,
CAST(payload.ShippingCity AS VARCHAR(20)) Shipping_City,
CAST(payload.ShippingState AS VARCHAR(10)) Shipping_State,
CAST(payload.ShippingPostalCode AS VARCHAR(5)) Shipping_Post_Code,
CAST(payload.ShippingCountry AS VARCHAR(20)) Shipping_Country,
CAST(payload.Industry AS VARCHAR(50)) Industry,
CAST(payload.Description AS VARCHAR(200)) Description,
CAST(payload.NumberOfEmployees AS INT) Num_Of_Employee,
CAST(payload.CustomerPriority__c AS VARCHAR(10)) Priority,
CAST(payload.Rating AS VARCHAR(10)) Rating,
CAST(payload.SLA__c AS VARCHAR(10)) SLA,
CAST(payload."Type" AS VARCHAR(20)) Customer_Type,
CAST(payload.Website AS VARCHAR(100)) Customer_Website,
CAST(payload.AnnualRevenue AS VARCHAR(10)) Annual_Revenue,
CAST(payload.LastActivityDate AS DATE) Last_Activity_Date
FROM READ_NOS (
ON (SELECT CAST(NULL AS JSON CHARACTER SET Unicode))
USING
LOCATION ('/S3/s3.amazonaws.com/ptctstoutput/salesforce/1ce190bc-25a9-4493-99ad-7497b497a0d0/903790813-2020-08-21T21:02:25')
ACCESS_ID ('A**********') /* AccessKeyId */
ACCESS_KEY ('***********') /* SecretAccessKey */
) AS D
) WITH DATA;Results from the salesforceReadNOS table:
SELECT * FROM salesforceReadNOS;
Another way of placing Amazon S3 data into a relational table is by "INSERT SELECT". Using this approach, the foreign table is the source table, while a newly created permanent table is the table to be inserted into. Contrary to the READ_NOS example above, this approach does require the permanent table be created beforehand.
One advantage of the INSERT SELECT method is that you can change the target table’s attributes. For example, you can specify that the target table be MULTISET or not, or you can choose a different primary index.
CREATE TABLE salesforcePerm, FALLBACK ,
NO BEFORE JOURNAL,
NO AFTER JOURNAL,
CHECKSUM = DEFAULT,
DEFAULT MERGEBLOCKRATIO,
MAP = TD_MAP1
(
Customer_Id VARCHAR(20) CHARACTER SET LATIN NOT CASESPECIFIC,
Customer_Name VARCHAR(100) CHARACTER SET LATIN NOT CASESPECIFIC,
Acct_Number VARCHAR(10) CHARACTER SET LATIN NOT CASESPECIFIC,
Billing_Street VARCHAR(20) CHARACTER SET LATIN NOT CASESPECIFIC,
Billing_City VARCHAR(20) CHARACTER SET LATIN NOT CASESPECIFIC,
Billing_State VARCHAR(10) CHARACTER SET LATIN NOT CASESPECIFIC,
Billing_Post_Code VARCHAR(5) CHARACTER SET LATIN NOT CASESPECIFIC,
Billing_Country VARCHAR(20) CHARACTER SET LATIN NOT CASESPECIFIC,
Phone VARCHAR(15) CHARACTER SET LATIN NOT CASESPECIFIC,
Fax VARCHAR(15) CHARACTER SET LATIN NOT CASESPECIFIC,
Shipping_Street VARCHAR(20) CHARACTER SET LATIN NOT CASESPECIFIC,
Shipping_City VARCHAR(20) CHARACTER SET LATIN NOT CASESPECIFIC,
Shipping_State VARCHAR(10) CHARACTER SET LATIN NOT CASESPECIFIC,
Shipping_Post_Code VARCHAR(5) CHARACTER SET LATIN NOT CASESPECIFIC,
Shipping_Country VARCHAR(20) CHARACTER SET LATIN NOT CASESPECIFIC,
Industry VARCHAR(50) CHARACTER SET LATIN NOT CASESPECIFIC,
Description VARCHAR(200) CHARACTER SET LATIN NOT CASESPECIFIC,
Num_Of_Employee INT,
Priority VARCHAR(10) CHARACTER SET LATIN NOT CASESPECIFIC,
Rating VARCHAR(10) CHARACTER SET LATIN NOT CASESPECIFIC,
SLA VARCHAR(10) CHARACTER SET LATIN NOT CASESPECIFIC,
Customer_Type VARCHAR(20) CHARACTER SET LATIN NOT CASESPECIFIC,
Customer_Website VARCHAR(100) CHARACTER SET LATIN NOT CASESPECIFIC,
Annual_Revenue VARCHAR(10) CHARACTER SET LATIN NOT CASESPECIFIC,
Last_Activity_Date DATE
) PRIMARY INDEX (Customer_ID);INSERT INTO salesforcePerm
SELECT
CAST(payload.Id AS VARCHAR(20)) Customer_ID,
CAST(payload."Name" AS VARCHAR(100)) Customer_Name,
CAST(payload.AccountNumber AS VARCHAR(10)) Acct_Number,
CAST(payload.BillingStreet AS VARCHAR(20)) Billing_Street,
CAST(payload.BillingCity AS VARCHAR(20)) Billing_City,
CAST(payload.BillingState AS VARCHAR(10)) Billing_State,
CAST(payload.BillingPostalCode AS VARCHAR(5)) Billing_Post_Code,
CAST(payload.BillingCountry AS VARCHAR(20)) Billing_Country,
CAST(payload.Phone AS VARCHAR(15)) Phone,
CAST(payload.Fax AS VARCHAR(15)) Fax,
CAST(payload.ShippingStreet AS VARCHAR(20)) Shipping_Street,
CAST(payload.ShippingCity AS VARCHAR(20)) Shipping_City,
CAST(payload.ShippingState AS VARCHAR(10)) Shipping_State,
CAST(payload.ShippingPostalCode AS VARCHAR(5)) Shipping_Post_Code,
CAST(payload.ShippingCountry AS VARCHAR(20)) Shipping_Country,
CAST(payload.Industry AS VARCHAR(50)) Industry,
CAST(payload.Description AS VARCHAR(200)) Description,
CAST(payload.NumberOfEmployees AS INT) Num_Of_Employee,
CAST(payload.CustomerPriority__c AS VARCHAR(10)) Priority,
CAST(payload.Rating AS VARCHAR(10)) Rating,
CAST(payload.SLA__c AS VARCHAR(10)) SLA,
CAST(payload."Type" AS VARCHAR(20)) Customer_Type,
CAST(payload.Website AS VARCHAR(100)) Customer_Website,
CAST(payload.AnnualRevenue AS VARCHAR(10)) Annual_Revenue,
CAST(payload.LastActivityDate AS DATE) Last_Activity_Date
FROM salesforce;SELECT * FROM salesforcePerm;Sample results:

Export Vantage Data to Amazon S3 Using NOS
I have a newleads table with 1 row in it on Vantage system.
![]()
Note there’s no address information for this lead. Let’s use the account information retrieved from Salesforce to update newleads table
UPDATE nl
FROM
newleads AS nl,
salesforceReadNOS AS srn
SET
Street = srn.Billing_Street,
City = srn.Billing_City,
State = srn.Billing_State,
Post_Code = srn.Billing_Post_Code,
Country = srn.Billing_Country
WHERE Account_ID = srn.Acct_Number;Now the new lead has address information.
![]()
Write the new lead information into S3 bucket using WRITE_NOS.
SELECT * FROM WRITE_NOS (
ON (
SELECT
Account_ID,
Last_Name,
First_Name,
Company,
Cust_Title,
Email,
Status,
Owner_ID,
Street,
City,
State,
Post_Code,
Country
FROM newleads
)
USING
LOCATION ('/s3/vantageparquet.s3.amazonaws.com/')
AUTHORIZATION ('{"Access_ID":"A*****","Access_Key":"*****"}')
COMPRESSION ('SNAPPY')
NAMING ('DISCRETE')
INCLUDE_ORDERING ('FALSE')
STOREDAS ('CSV')
) AS d;Where Access_ID is the AccessKeyID, and Access_Key is the SecretAccessKey to the bucket.
Create an Amazon S3 to Salesforce Flow
Repeat Step 1 to create a flow using Amazon S3 as source and Salesforce as destination.
Step 1. Specify flow details
This step provides basic information for your flow.
Fill in Flow name (i.e., vantage2sf) and Flow description (optional), leave Customize encryption settings (advanced) unchecked. Click Next.
Step 2. Configure flow
This step provides information about the source and destination for your flow. For this example, we will be using Amazon S3 as the source, and Salesforce as the destination.
-
For Source details, choose Amazon S3, then choose the bucket where you wrote your CSV file to (i.e. vantagecsv)
-
For Destination details, choose Salesforce, use the connection you created in Step 1 from the drop-down list for Choose Salesforce connection, and Lead as Choose Salesforce object.
-
For Error handling, use the default Stop the current flow run.
-
Flow trigger is Run on demand. Click Next.
Step 3. Map data fields
This step determines how data is transferred from the source to the destination.
-
Use Manually map fields as Mapping method
-
Use Insert new records (default) as Destination record preference
-
For Source to destination filed mapping, use the following mapping
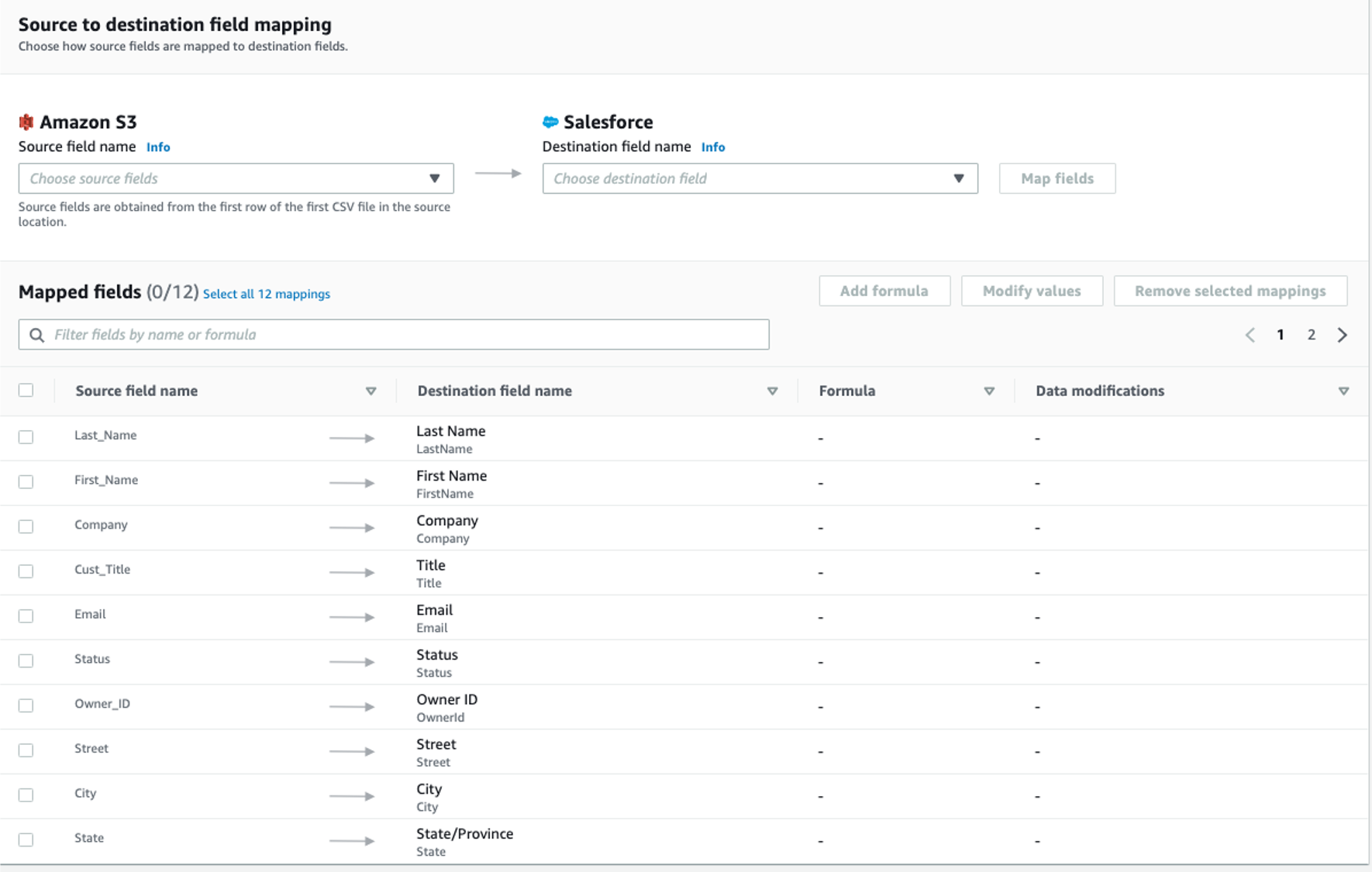

-
Click Next.
Step 4. Add filters
You can specify a filter to determine which records to transfer. For this example, no filter is added. Click Next.

Cleanup (Optional)
Once you are done with the Salesforce data, to avoid incurring charges to your AWS account (i.e., AppFlow, Amazon S3, Vantage and VM) for the resources used, follow these steps:
-
AppFlow:
-
Delete the "Connections" you created for the flow
-
Delete the flows
-
-
Amazon S3 bucket and file:
-
Go to the Amazon S3 buckets where the Vantage data file is stored, and delete the file(s)
-
If there are no need to keep the buckets, delete the buckets
-
-
Teradata Vantage Instance
-
Stop/Terminate the instance if no longer needed
-
| If you have any questions or need further assistance, please visit our community forum where you can get support and interact with other community members. |