Google Cloud Vertex AI Pipelines Vantage BYOM Housing Example
Get this notebook in .ipynb format.
Vertex AI is Google's single environment for data scientists to develop and deploy ML models, from experimentation, to deployment, to managing and monitoring models. In this tutorial, we will show how to integrate Vantage Analytics capabilites in Vertex AI ML Pipelines. We'll create two pipelines:
Training - the first will be a three step pipeline to train and deploy a model; the first step transforms data in Vantage and then exports a file for training, the second step trains a model using scikit-learn, and the final step deploys the model to Vantage using Bring Your Own Model (BYOM) feature of Teradata Vantage.
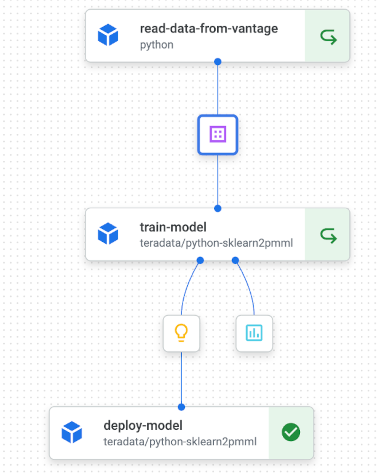
Scoring - the second pipeline will use the model created by the the first pipeline to score new data stored in a table on Vantage.
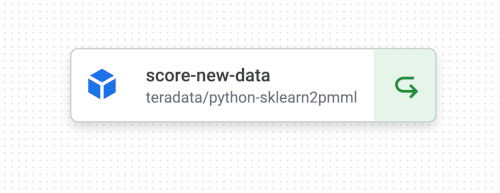
Both pipelines are very simple, but the first pipeline could be triggered to retrain a model with new data when the production model has drifted. The second pipeline could be run on a regular schedule when new data for scoring was available.
Prerequisites¶
import sys
!{sys.executable} -m pip install --upgrade --force-reinstall ipython-sql
!{sys.executable} -m pip install teradatasqlalchemy teradataml kaggle ipython-sql kfp
Setup a Vantage instance¶
Follow the Run Vantage Express on Google Cloud how-to to get Vantage setup. Make sure to follow the instructions to open the VM up to the Internet.
Create GCS bucket¶
You will need a GCS bucket to store artifacts managed by KubeFlow.
Define the bucket name:
BUCKET_NAME = "<your-bucket-name>"
If the bucket doesn't exist, go ahead and create it:
!gsutil ls -b gs://$BUCKET_NAME || gsutil mb gs://$BUCKET_NAME
Give permissions to Vertex AI to access your bucket¶
Go to IAM tab in GCS console and assign Storage Admin role to your default Compute Engine. The principal of the default Compute Engine account looks like this: <project-id>-compute@developer.gserviceaccount.com.
Download sample data¶
We'll use the Boston Housing dataset which can be obtained from Kaggle.
Login to your Kaggle account. In the top right corner click on your user icon and select Account. Find API section and click on Create New API Token. This will produce kaggle.json file. Open kaggle.json and copy the username and key. Substitute the values in the cell and run it:
%env KAGGLE_USERNAME=<your-kaggle-username>
%env KAGGLE_KEY=<your-kaggle-key>
!kaggle datasets download -f housing.csv vikrishnan/boston-house-prices
Load training data to Vantage¶
Let's setup DATABASE_URL environment variable that will point to your instance of Vantage. Make sure that you default to mldb database where BYOM package is installed, e.g.:
DATABASE_URL='teradatasql://dbc:dbc@34.121.78.209/mldb'
%env DATABASE_URL=$DATABASE_URL
import pandas
import os
df=pandas.read_fwf('housing.csv', names=['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV'])
df.to_sql('housing', con=DATABASE_URL, index=False)
For this tutiorial we need a table to store the trained model and another table with some new data that we want to score with our model. Use teradatasql to execute the following SQL on your Vantage instance.
%%sql
CREATE SET TABLE demo_models (model_id VARCHAR (30), model BLOB) PRIMARY INDEX (model_id);
CREATE SET TABLE test_housing (ID INTEGER, CRIM FLOAT, ZN FLOAT,INDUS FLOAT,CHAS INTEGER,NOX FLOAT,RM FLOAT,
AGE FLOAT,DIS FLOAT, RAD INTEGER,TAX INTEGER,PTRATIO FLOAT,B FLOAT,LSTAT FLOAT) PRIMARY INDEX (CRIM);
INSERT INTO test_housing (ID, CRIM, ZN, INDUS, CHAS, NOX, RM, AGE, DIS, RAD, TAX, PTRATIO, B, LSTAT)
VALUES (1,.02,0.0,7.07,0,.46,6.4,78.9,4.9,2,242,17.8,396.9,9.14);
The first pipeline to train and deploy a model using Kubeflow¶
Now we are ready to create the components in the pipeline. Vertex AI Pipelines can run pipelines built using the Kubeflow Pipelines SDK or TensorFlow Extended. We'll be using the Kubeflow Pipelines SDK for this simple example using scikit-learn.
In this example we will create the following three components:
read_data_from_vantage- input: ipaddr of the VM hosting Vantage
- output: csv file with the data for training and testing
train_model- input: csv file with data for training and testing
- output: file containing the model
- output: Metric artifact with model performance
deploy_model- input: file containing the model
First, import the Kubeflow Pipeline component and dsl packages.
import kfp.v2.dsl as dsl
from kfp.v2.dsl import (
component,
Input,
Output,
Dataset,
Model,
Metrics,
)
Create the component that reads data from Vantage¶
The first component reads data from a Vantage warehouse (see above and make sure you have set up Vantage Express in Google Cloud including opening up a firewall to the VM so you can access Vantage from the Internet.)
The component connects to Vantage using the connection string passed as an input parameter, reads the rows from the table mldb.housing in Vantage and then outputs the data to an Output[Dataset]. The Output is a temporary file used to pass data between components (see more about passing data between components here).
The component uses sqlalchemy to talk to Teradata. Each component is run in a separate container on Kubernetes so all import statements need to be done within the component. We have created a base image with teradatasql already installed. When you pass base_image='python' the component will use that image to create a container. packages_to_install parameter defines what other packages the component needs.
@component(base_image='python', packages_to_install=['teradatasqlalchemy'])
def read_data_from_vantage(
connection_string: str,
output_file: Output[Dataset]
):
import sqlalchemy
file_name = output_file.path
engine = sqlalchemy.create_engine(connection_string)
with engine.connect() as con:
rs = con.execute('SELECT * FROM housing')
with open(output_file.path, 'w') as output_file:
output_file.write('CRIM,ZN,INDUS,CHAS,NOX,RM,AGE,DIS,RAD,TAX,PTRATIO,B,LSTAT,MEDV\n')
for row in rs:
output_file.write(','.join([str(i) for i in row]) + '\n')
Create the train model component¶
Next we'll create a component to train a model with the training data.
The input into this component is the file from the previous component. The output is the file with the trained model using joblib.dump and a file with the test data.
The component will use scikit-learn and pandas so we need to pass packages_to_install=['pandas==1.3.5','scikit-learn'] - this will tell Kubeflow to install the packages when the container is created.
@component(base_image='teradata/python-sklearn2pmml', packages_to_install=['pandas==1.3.5','scikit-learn','sklearn-pandas==1.5.0'])
def train_model(
input_file : Input[Dataset],
output_model: Output[Model],
output_metrics: Output[Metrics]
):
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.preprocessing import StandardScaler
from sklearn import metrics
from sklearn_pandas import DataFrameMapper
import joblib
from sklearn2pmml.pipeline import PMMLPipeline
from sklearn2pmml import sklearn2pmml
df = pd.read_csv(input_file.path)
train, test = train_test_split(df, test_size = .33)
train = train.apply(pd.to_numeric, errors='ignore')
test = test.apply(pd.to_numeric, errors='ignore')
target = 'MEDV'
features = train.columns.drop(target)
pipeline = PMMLPipeline([
("mapping", DataFrameMapper([
(['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT'], StandardScaler())
])),
("rfc", RandomForestRegressor(n_estimators = 100, random_state = 0))
])
pipeline.fit(train[features], train[target])
y_pred = pipeline.predict(test[features])
metric_accuracy = metrics.mean_squared_error(y_pred,test[target])
output_metrics.log_metric('accuracy', metric_accuracy)
output_model.metadata['accuracy'] = metric_accuracy
joblib.dump(pipeline, output_model.path)
Create component to deploy model¶
The last component loads the model and tests it on the test data. The Output[Metrics] creates an artifact with the models performance and can be visualize in the Runtime Graph.
@component(base_image='teradata/python-sklearn2pmml')
def deploy_model(
connection_string: str,
input_model : Input[Model],
):
import sqlalchemy
import teradataml as tdml
import joblib
from sklearn2pmml.pipeline import PMMLPipeline
from sklearn2pmml import sklearn2pmml
engine = sqlalchemy.create_engine(connection_string)
tdml.create_context(tdsqlengine = engine)
pipeline = joblib.load(input_model.path)
sklearn2pmml(pipeline, "test_local.pmml", with_repr = True)
model_id = 'housing_rf'
model_file = 'test_local.pmml'
table_name = 'demo_models'
tdml.configure.byom_install_location = "mldb"
try:
res = tdml.save_byom(model_id = model_id, model_file = model_file, table_name = table_name)
except Exception as e:
# if our model exists, delete and rewrite
if str(e.args).find('TDML_2200') >= 1:
res = tdml.delete_byom(model_id = model_id, table_name = table_name)
res = tdml.save_byom(model_id = model_id, model_file = model_file, table_name = table_name)
pass
else:
raise
Create function for executing the pipeline¶
Now we'll create a function to execute each component in the pipeline.
@dsl.pipeline(
name='run-vantage-pipeline',
description='An example pipeline that connects to Vantage.',
)
def run_vantage_pipeline_vertex(
connection_string: str
):
data_file = read_data_from_vantage(connection_string).output
test_model_data = train_model(data_file)
deploy_model(connection_string,test_model_data.outputs['output_model'])
Compile the pipeline. The pipline will be saved in a json file with the name provided as the package_path.
from kfp.v2 import compiler
compiler.Compiler().compile(pipeline_func=run_vantage_pipeline_vertex,
package_path='train_housing_pipeline.json')
Now use the Vertex AI client to execute the pipeline. Import the google.cloud.aiplatform package. Vertex AI needs a Cloud Storage bucket to for temporary files. Create a new job using the json file above and pass the ipaddr as the parameter. Then submit the job.
When the job starts a link will appear that will take you to the Runtime Graph.
import google.cloud.aiplatform as aip
pipeline_root_path = 'gs://' + BUCKET_NAME
job = aip.PipelineJob(
display_name="housing_training_deploy",
template_path="train_housing_pipeline.json",
pipeline_root=pipeline_root_path,
parameter_values={
'connection_string': DATABASE_URL
}
)
job.submit()
Inspect model metrics¶
When the pipeline has completed running (each component in the graph should have a green check mark). You can click on each component to see details of the execution and the logs created. If you click on the output_metrics artifact, in the Pipeline run analysis window the Node Info will show the accuracy of the model. Yyou can learn more about other metrics you can pass and visulation using the Metrics artifict here.)
Test the deployed model¶
Let's test the model we have just deployed by scoring some new data. We'll use the teradataml driver to retrieve the saved model and score the rows in a table with new data.
import teradataml as tdml
import sqlalchemy
import os
engine = sqlalchemy.create_engine(DATABASE_URL)
eng = tdml.create_context(tdsqlengine = engine)
#indicate the database that BYOM is using
tdml.configure.byom_install_location = "mldb"
tdf_test = tdml.DataFrame('test_housing')
modeldata = tdml.retrieve_byom("housing_rf", table_name="demo_models")
predictions = tdml.PMMLPredict(
modeldata = modeldata,
newdata = tdf_test,
accumulate = ['ID']
)
predictions.result.to_pandas()
Create a new pipeline to score new data¶
This pipeline will have only one component that uses the teradatasql driver to execute a SQL query that retrieves the model from the demo_model table and scores the rows in the test_housing table.
@component(base_image='teradata/python-sklearn2pmml', packages_to_install=['pandas==1.3.5','scikit-learn'])
def score_new_data(
connection_string: str,
model_name: str,
model_table: str,
data_table: str,
prediction_table: str
):
import teradataml as tdml
import sqlalchemy
engine = sqlalchemy.create_engine(connection_string)
with engine.connect() as con:
con.execute(f'CREATE TABLE {prediction_table} AS (SELECT * FROM mldb.PMMLPredict ( ON {data_table} ON (SELECT * FROM {model_table} where model_id=\'{model_name}\') DIMENSION USING Accumulate (\'ID\')) AS td ) WITH DATA')
The run_new_data_score pipeline takes the following parameters:
model_name: ID of the modelmodel_table: the name of the table storing the modeldata_table: the name of the table with new data to scoreprediction_table: the name of the table to store the scoring results
When the pipeline is executed the dashboard will provide fields to enter the values you want to use.
@dsl.pipeline(
name='new-data-pipeline',
description='An example of a component that scores new data with a saved model.',
)
def run_new_data_score(
connection_string: str,
model_name: str,
model_table: str,
data_table: str,
prediction_table: str
):
score_new_data(DATABASE_URL,model_name,model_table,data_table,prediction_table)
To compile the pipeline run the following code. The pipeline will be saved in score_new_data_pipeline_sql.json file.
compiler.Compiler().compile(pipeline_func=run_new_data_score,
package_path='score_new_data_pipeline_sql.json')
We will now execute the pipeline in Vertex AI Pipelines.
import google.cloud.aiplatform as aip
pipeline_root_path = 'gs://' + BUCKET_NAME
job = aip.PipelineJob(
display_name="new_data_housing",
template_path="score_new_data_pipeline_sql.json",
pipeline_root=pipeline_root_path,
parameter_values={
'connection_string': DATABASE_URL,
'model_name': 'housing_rf',
'model_table': 'demo_models',
'data_table': 'test_housing',
'prediction_table': 'housing_predictions'
}
)
job.submit()
Once the job completes, you can view the batch predictions with:
%%sql
SELECT * FROM housing_predictions;
Cleanup¶
To stop incurring charges you need to clean up the following resources:
- Delete the Vantage Express VM - go to the list of Compute Engine instances and selecting the instance with Vantage Express and then click on
Delete. - Delete the storage bucket you configured